← Back to Projects

SwapKV
Mentored by: Pliops
High-performance key-value store with memory swapping capabilities
C++
Redis
LevelDB
gRPC
Docker
Kubernetes
Description
A distributed key-value storage system with intelligent memory management and swapping mechanisms. Designed for handling large datasets that exceed available RAM by efficiently swapping data between memory and disk. Features include consistent hashing, replication, and automatic failover for high availability.
Team Members
Cohort: Embedded Systems Bootcamp 2025 (Embedded)
Responsibilities:
Performed an in-depth vLLM internals study: traced scheduler v1/SchedulerInterface, KVCacheManager & BlockSpaceManager, attention backends (Flash/MLA), and existing KV connectors; built small probes to profile KV lifecycles and HBM↔CPU memory paths, documenting findings (diagrams/notes) that guided the connector design.
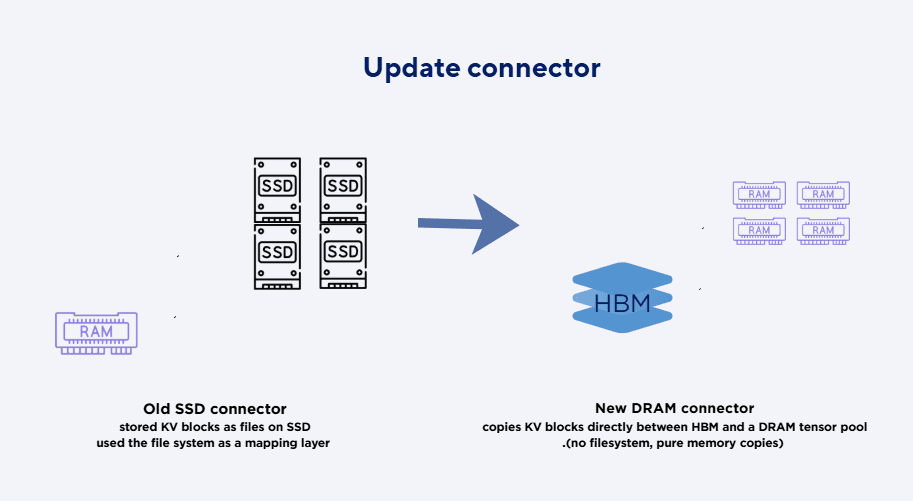
Designed and implemented HBMDramManager and TensorPool (memmap//dev/shm-backed) to stage KV-cache blocks in CPU DRAM with clean save/load/free APIs.
Built the vLLM v1 KV connector (HbmDramConnector) extending KVConnectorBase_V1, including metadata, block protocol, and KVTransferConfig integration.
Created a runtime layer residency map (layer → GPU/CPU) and operations hbmtodram / dramtohbm / freefromdram / get_location.
Responsibilities:
Developed understanding of Transformer-LLM architecture and researched the internal design of the vLLM library.
Ran profiling tools (such as SnakeViz) to understand the execution flow inside the vLLM library
Performed systematic debugging throughout the development process.
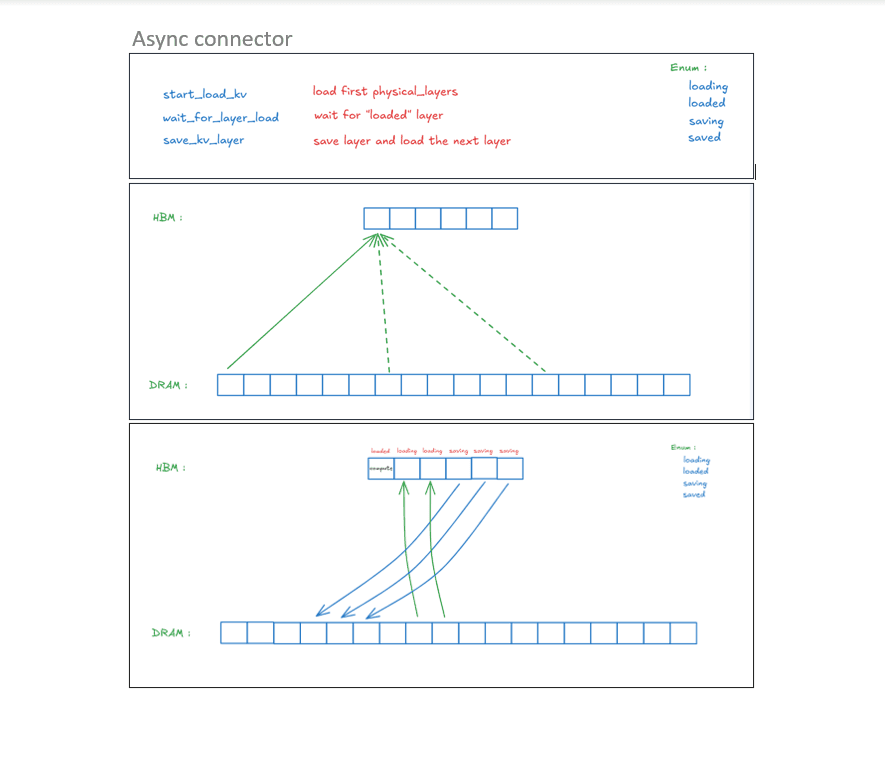
Refactored the connector from a synchronous to a smarter, asynchronous execution model.
Responsibilities:
Installed and configured vLLM on CPU and GPU environments.
Research: Debugged C++ and Python components to analyze system behavior.
Research: Studied core concepts of LLMs and the vLLM architecture.
Built an initial connector for saving KV-cache layers to persistent storage.
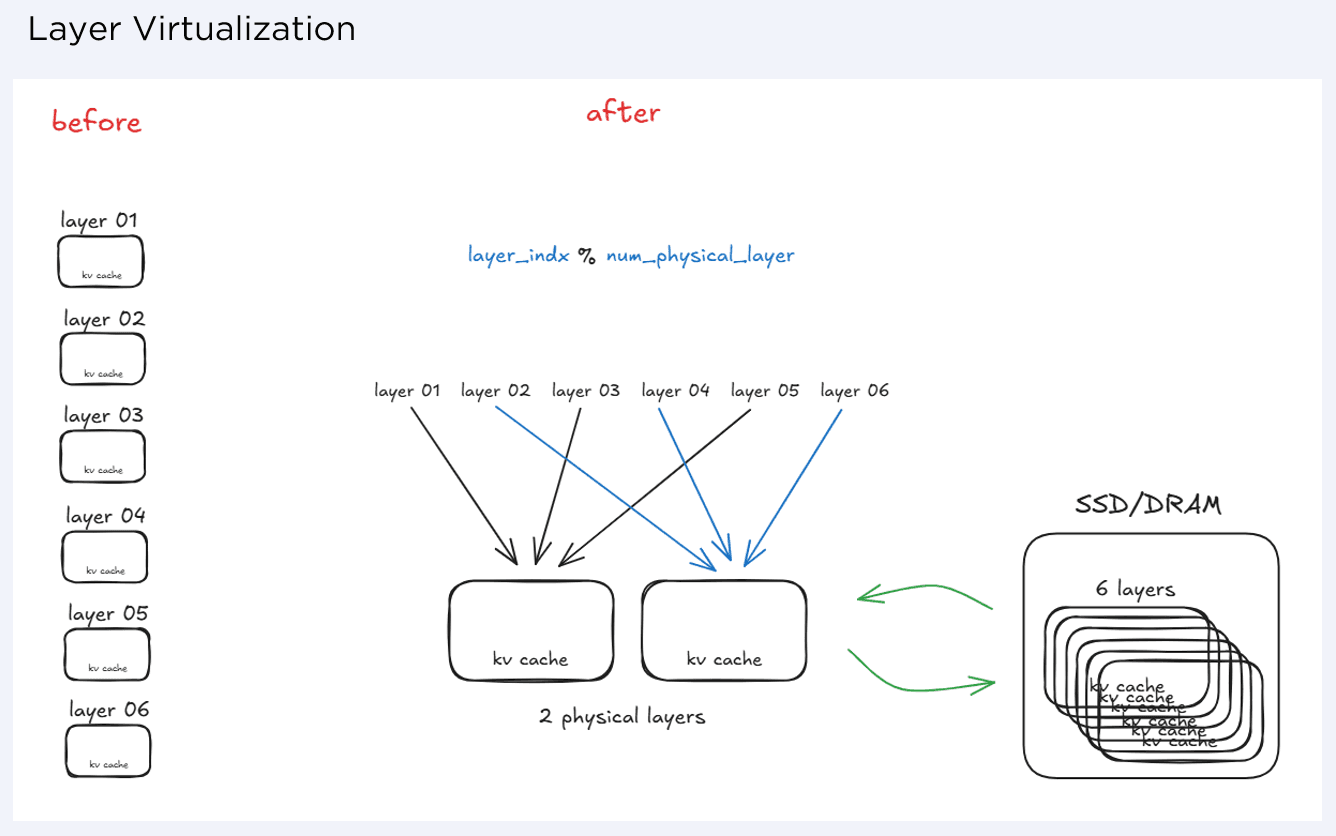
Implemented KV-cache virtualization across HBM and external memory, keeping only active layers in HBM and fetching others on demand, while maintaining correct model outputs.
Identified bottlenecks using performance-profiling tools (Nsight).
...and more contributions not listed here