← Back to Projects
onnx runtime
Mentored by: Mobileye
Deep debugging and kernel-level contributions to ONNX Runtime
C++
ONNX Runtime
Quantization (INT8
QDQ)
Protobuf
Kernel Debugging
CPU EP
CUDA/TensorRT/OpenVINO EP behaviors
Description
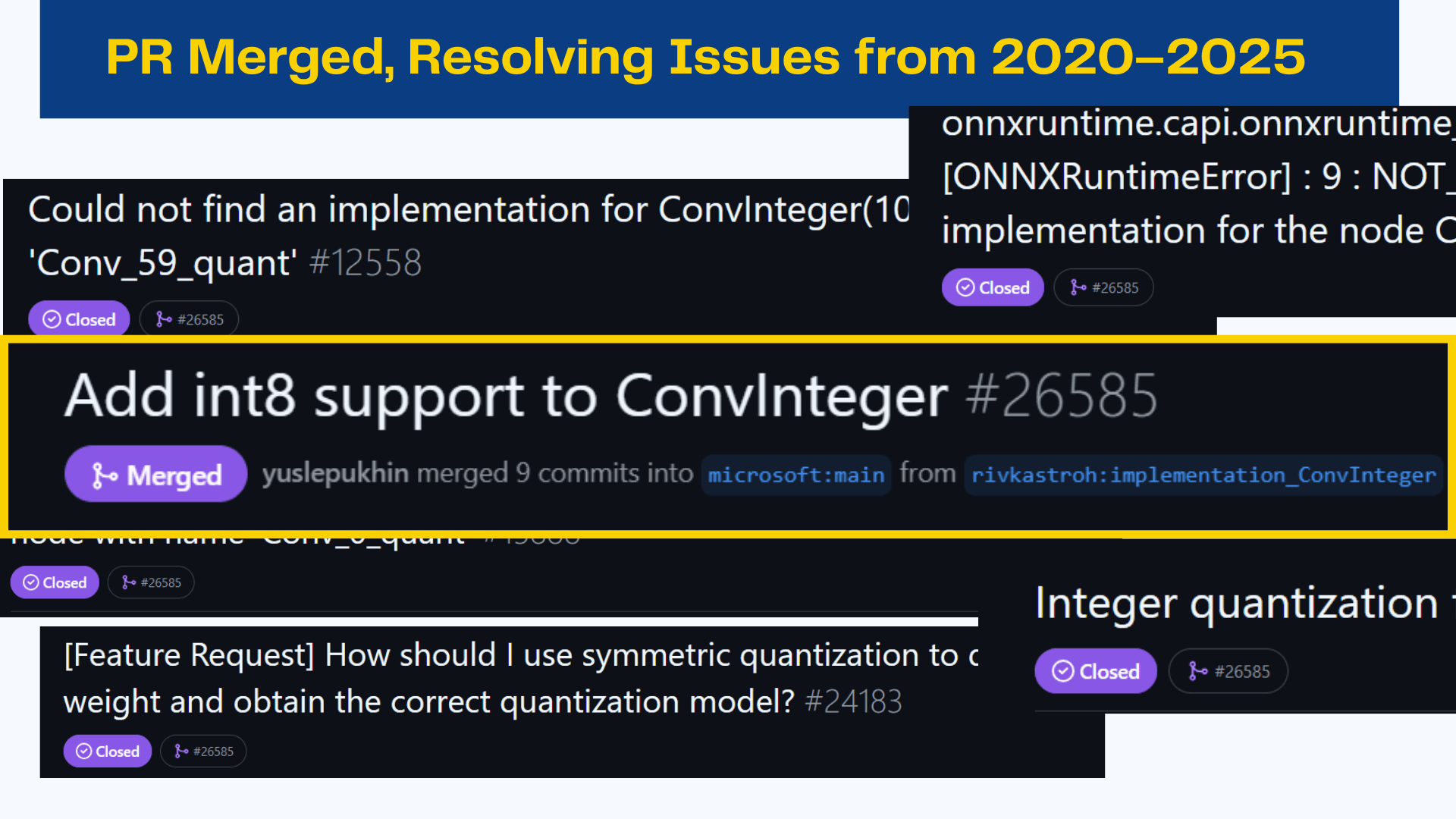
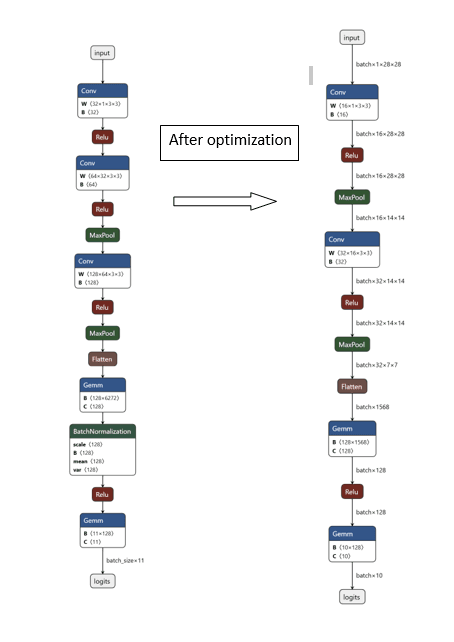
Fixes and enhancements across ONNX Runtime CPU Execution Provider: QuantizeLinear kernel mismatch (Issue #25362), MatMulNBits extension for 3D weight support, QDQ graph quantization bug fixes, Reduce op PRE/POST broadcasting corrections, full ONNX/NumPy-compliant broadcasting implementation for LayerNorm/RMSNorm, and multiple PRs resolving issues from 2020–2025. Includes deep tracing through kernel registration, type constraints, and execution graph selection logic.
Team Members
Cohort: Embedded Systems Bootcamp 2025 (Embedded)

Responsibilities:
Contributed Production-level C++ fixes to Microsoft's ONNX Runtime, focusing on correctness, full specification compliance ,and performance optimizations.
Designed and implemented a spec-compliant generic mechanism for all Reduce operators, fixing correctness issues for empty-axes cases and adding optimized fast-paths for operators that do not require pre/post-processing.
After implementing the fix in the CPU Execution Provider, I identified that other EPs still exhibited the incorrect behavior and opened a formal Issue recommending aligning them with the corrected CPU implementation.
Added full broadcasting support to RMSNormalization and LayerNormalization, implementing a complete spec-compliant solution while preserving the previous partial implementation as an optimized fast-path for common model cases.
Developed comprehensive test coverage for all fixes, including targeted GTest unit tests and large-scale fuzz testing that generated tens of thousands of randomized shape combinations to validate operator correctness.
Collaborated with Microsoft maintainers throughout the contribution process, including diagnosing CI failures, addressing code review feedback, running linters, and ensuring all changes aligned with ONNX Runtime’s design and coding standards.
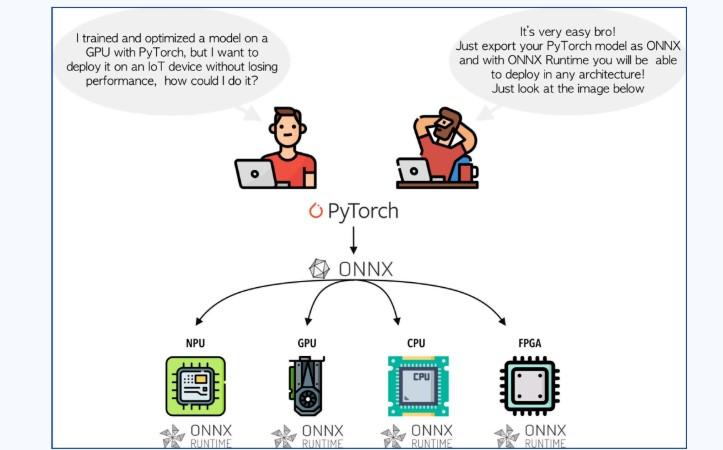
Optimized deep learning models using ONNX Runtime, performing CPU/GPU performance profiling (latency, throughput, batch size) and applying techniques such as quantization, pruning, and knowledge distillation—while evaluating their impact on model accuracy and computational efficiency.
...and more contributions not listed here
Responsibilities:
Analyzed ONNX Runtime source (C++/Python) to understand and improve optimization flows, quantization mechanisms (static/dynamic), and operators such as ConvInteger and MatMulInteger.
Analyzed quantization logic (formulas, differences between symmetric/asymmetric, static/dynamic behavior).
Investigated the quantization structure in ORT – examining how Q/DQ layers are created, and the flow of tensor registration versus the actual quantization flow.
Examined the implementation of quantization in the source code – the model’s runtime behavior after quantization, understanding the Graph Optimization process, and writing documentation explaining the mechanisms and overall system flow.
Investigated and resolved issues by debugging errors, using Netron to view the ONNX graph, and finding the root cause.
Fixed input constraints for kernels and implemented operator computation (including handling hard-coded cases).
Added tests for operators to cover input/output scenarios and verify correct behavior after kernel code fixes and changes.
Refactored functions and names to clearly separate the tensor-registration stage from the actual quantization-execution stage.
Measured and compared FP32 vs INT inference performance (profiling, CPU time, wall-clock time) to analyze quantization impact on latency.
Providing support and assistance to ORT users.
...and more contributions not listed here
Responsibilities:
• Analyzed and experimented with model optimization techniques for Edge AI deployment, focusing on performance profiling and parameter tuning (e.g., batch size, CPU vs. GPU latency, and throughput).
• Applied Quantization, Pruning, and Knowledge Distillation to optimize cutting-edge models (e.g., YOLOv8, LPRNet, BLIP-2, LLaMA 2, MNIST) for improved inference performance on constrained devices
• Gained hands-on experience with leading AI frameworks including ONNX Runtime and OpenVINO, performing profiling, compilation, and ad-hoc optimization to maximize inference performance.
• Collaborated within the Inference Optimization Team to connect model-level insights with infrastructure-level execution improvements.
• Explored, debugged, and tested the ONNX Runtime C++ codebase, adding unit tests to deepen understanding of core operators and to analyze reported issues in the open-source repository
...and more contributions not listed here
Responsibilities:
Optimized large language models and computer vision networks for edge devices through pruning, quantization, and distillation, using profiling to balance inference latency, memory footprint, and accuracy.
Investigated a failure where a statically INT8-quantized model could not start, reproducing the issue and tracing it to the QuantizeLinear operator in opset 23.
Mapped how the inference engine builds its execution graph and selects kernels for each node, to understand why a registered QuantizeLinear kernel was still not chosen.
Analyzed how the model format uses Protobuf to describe tensors and type constraints, and compared QuantizeLinear’s official schema with the engine’s constraints to locate the mismatch.
Aligned the QuantizeLinear kernel’s type constraints with the official schema, verified that INT8-quantized models now run correctly, and contributed the fix as an open-source pull request.
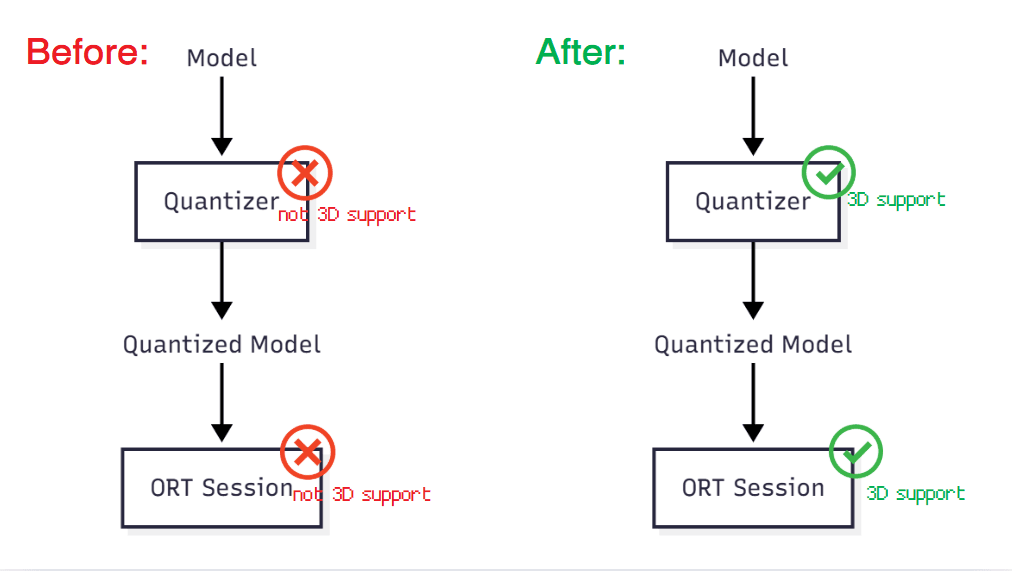
Updated the MatMulNBits quantizer so it no longer rejects 3D weight tensors, adding logic that iterates over the third dimension and produces a correctly quantized weight slice for each batch.
Adapted the MatMulNBits runtime kernel to treat 3D weights as a batched matrix, computing a common batch size and looping over the batch dimension so that each slice is multiplied with the input using the optimized N-bit GEMM path.
Implemented GoogleTest and pytest unit and integration tests for quantized operators to ensure numerical correctness and protection against regressions.
...and more contributions not listed here