← Back to Projects
Weighted Matching in a Poly-Streaming Model
Mentored by: Next Silicon
Efficient weighted matching algorithms for poly-streaming graph processing
C++
Graph Algorithms
Streaming Algorithms
Approximation Theory
Data Structures
Description
Advanced graph algorithms for computing weighted matchings in poly-streaming computational models. Addresses challenges of processing large graphs with limited memory by using streaming techniques. Includes approximation algorithms, theoretical guarantees, and practical implementations for real-world graph problems.
Team Members
Cohort: Embedded Systems Bootcamp 2025 (Embedded)
Responsibilities:
Implemented the core poly-streaming maximum weight matching (PS-MWM) algorithm in C++ based on the “Weighted Matching in a Poly-Streaming Model” paper, including per-thread stacks and dual variables.
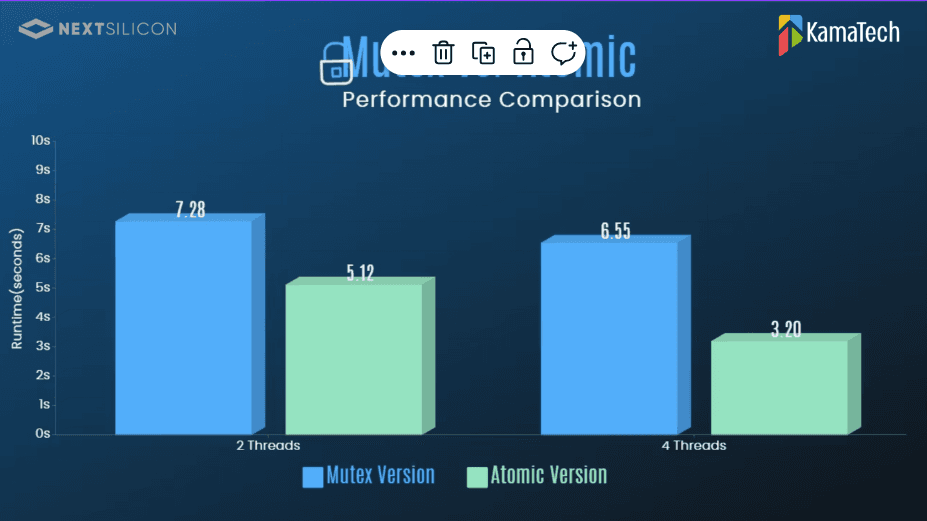
Replaced a mutex-based synchronization scheme with a hybrid atomic design that reduced contention between threads and improved parallel runtime.
Performed detailed performance profiling (perf + Google Benchmark) to identify mutex contention, measure scalability, and guide low-level optimizations.
Designed and implemented multi-processor parallelization of the streaming algorithm, including thread creation, work distribution across streams, and synchronization.
Added NUMA-aware execution by grouping threads per socket, partitioning data structures per NUMA node, and ensuring local memory access for each thread group.
Implemented and maintained CI pipelines (GitHub Actions) for automatic build, tests, and basic checks on the PS-MWM codebase.
Research: Evaluated alternative synchronization strategies (pure mutex vs. hybrid atomics) and multi-processor configurations to understand their impact on performance.
...and more contributions not listed here

Responsibilities:
Developed a parallel real-time streaming algorithm in C++ inspired by “Weighted Matching in a Poly Streaming Model” (ESA 2025), including trade-offs analysis for runtime, memory and accuracy.
Implemented multithreading with NUMA-aware optimization on multi-socket servers, improving cache locality, managing global/local state, and reducing contention using atomic operations and hybrid locking.
Performed in-depth profiling using perf and Google Benchmark, analyzing runtime, scaling, and memory usage across all algorithm variants.
Validated solution quality on real RB/Pajek datasets, using the LEMON library for accurate graph processing and correctness checks.
Integrated extensive unit and integration tests using Google Test, combined with an automated CI pipeline (GitHub Actions) to to maintain correctness and stability across all variants.
Researched cloud-based data access; evaluated direct reading and compressed datasets, but avoided it due to latency and decompression overhead.
Built cross-platform CMake infrastructure, worked with GitHub code reviews, and deployed on WSL2 and HPC Linux environments for full portability.
Achieved 60–80× speedup on large graphs, with solution quality aligned to theoretical guarantees and near-linear multithreaded scaling.
...and more contributions not listed here

Responsibilities:
Implemented several optimized algorithmic variants of the Poly-Streaming Maximum Weight Matching algorithm in C++, enabling scalable, high-performance graph processing based on an academic research model.
Implemented efficient synchronization mechanisms that reduced contention and improved scalability and stability across multi-core parallel environments.
implemented a NUMA-aware variant of the algorithm, ensuring locality-optimized memory usage, reduced remote access, and improved performance on multi-socket systems.
Developed a comprehensive test suite with Google Test and integrated it into a CI pipeline (GitHub Actions) to automatically run unit and integration tests, ensuring correctness and code quality across the project.
Used Sanitizers and perf to identify performance bottlenecks and achieve significant runtime improvements.
Used CMake to build a clean and modular system, working in a Linux environment
Research: Cloud Data Access – Investigated loading compressed graph datasets directly from cloud storage to reduce local disk usage, experiments showed that latency and decompression overhead made this approach impractical for high-performance runs.
...and more contributions not listed here