← Back to Projects
Hyperconverged KV-Cache Offloading for Cost-Efficient LLM Inference
Mentored by: Pliops
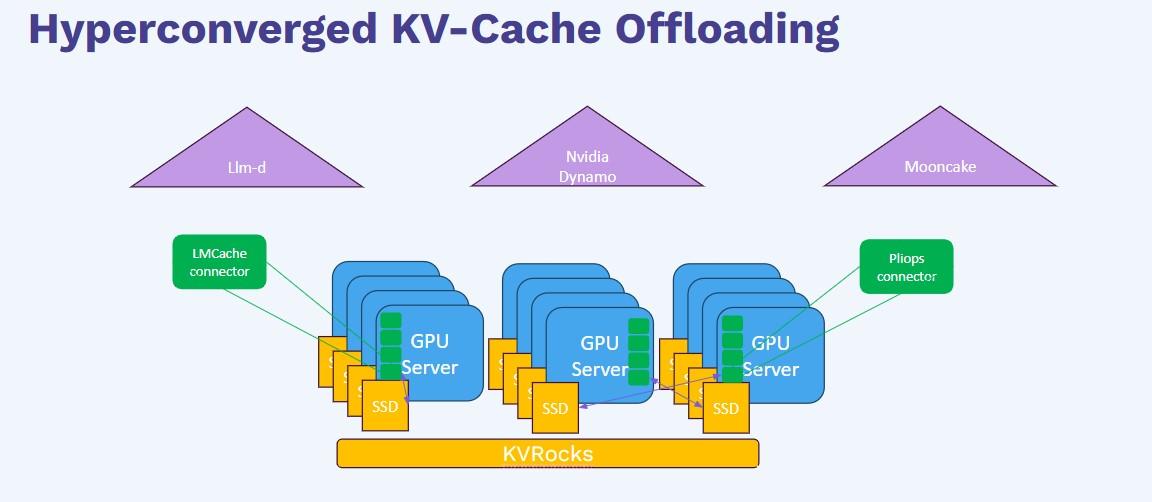
Datacenter-scale LLM inference framework that offloads KV-cache to a hyperconverged KV-store, increasing capacity and robustness while keeping high hit-rates and good user experience.
Python
CUDA
vLLM
TRT-LLM
SGLang
LMCache
KVRocks
NVIDIA Dynamo
Kubernetes (k3s)
RocksDB
LZ4
asyncio
Description
Designed and evaluated a hyperconverged KV-cache offloading layer for LLM inference, including KV-cache aware routing, full KV-cache mapping, and resource-aware policies. They benchmarked NVIDIA Dynamo vs LLM-D with and without LMCache, analyzed hit-rate vs performance trade-offs, investigated DRAM usage in the MOONCAKE runtime, and integrated LMCache with KVRocks and a custom Pliops connector. The project included Kubernetes-based deployments, GPU/CPU cache sizing calculations, and robustness improvements such as timeout handling and failure-safe clients.
Team Members
Cohort: Data Science Bootcamp 2025 (Data)
Responsibilities:
Research and Familiarization with vLLM Conducted in-depth study of the vLLM architecture, execution flow, and inference pipeline. Executed multiple LLM inference runs using vLLM to gain hands-on operational understanding.
Research and Evaluation of KVRocks Investigated the KVRocks storage engine, its design goals, architecture, and usage scenarios. Evaluated its suitability as an external KV-store for inference KV-cache offloading.
Baseline vLLM Deployment on NVIDIA L4 GPUs Deployed the open-source vLLM framework on NVIDIA L4 GPUs to establish a baseline environment. Executed Llama-3-8B inference workloads to measure initial performance characteristics.
Concurrency Limit Analysis Based on GPU HBM Saturation Calculated precise concurrency limits by analyzing HBM saturation points relative to token size and KV-cache footprint. Derived the maximum number of concurrent clients supported per server.
Integration Between vLLM and the Pliops Gateway Integrated vLLM with the Pliops Gateway (connector) for accelerated KV access. Validated full end-to-end inference flow through the gateway.
Implementation of a New Storage Backend for KVRocks in the Gateway Developed and integrated a new KVRocks storage backend within the Pliops Gateway. Implemented full CRUD support for direct interaction with the KV-store.
Single-Threaded Multi-Get / Multi-Set Implementation Implemented a single-threaded Multi-Get / Multi-Set access pattern to KVRocks. Evaluated correctness, stability, and latency impact of batched operations.
Multi-Threaded Get/Set Integration via the Gateway Implemented a multi-threaded Get/Set access pattern with multiple concurrent clients. Managed connection handling, synchronization, and system stability under load.
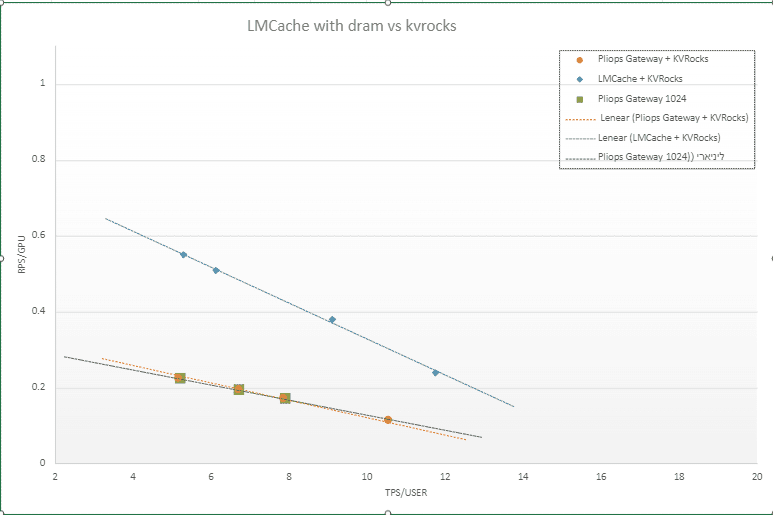
Performance Benchmarking and Comparative Storage Analysis Executed performance benchmarks comparing vLLM + Pliops Gateway + KVRocks against vLLM with DRAM-based LM-Cache. Synthesized benchmark data into comparative DRAM vs. SSD graphs, plotting RPS/GPU vs. TPS/USER to illustrate cost–performance trade-offs.
Bottleneck Analysis and Performance Optimization Insights Analyzed logs and performance metrics to identify I/O, networking, and memory bottlenecks. Derived initial optimization insights and future improvement directions.
...and more contributions not listed here

Responsibilities:
Hyper-Converged KV-Cache Offloading As part of a research-driven team project, each member was assigned a specific topic to investigate, build, and benchmark. My focus was on executing Mooncake and analyzing how it manages memory retention from vLLM within a hyper-converged design. This included hands-on work with KV-Cache optimization for key-value storage and evaluating system behavior under different inference loads.
vLLM Research & System Architecture Analysis Conducted in-depth research into vLLM and execution flow, as well as a detailed study of MOONCAKE’s architecture to fully understand system behavior, request flow, and pipeline dynamics.
Performed full setup and execution of the Mooncake project on a PLIOPS server from open source, including build, dependency installation, and runtime validation. Handled various deployment challenges, including crashes, server-specific build adjustments, and CUDA incompatibility with the MOONCAKE requirements. Requested the appropriate CUDA version to be installed, and later resolved a Python version mismatch by switching to a compatible interpreter.
Assisted a PLIOPS employee in analyzing high DRAM usage (~1GB for 2 keys) when running models on Mooncake. Replicated the test on a different server using a different model and script, as the benchmark he used exceeded the available GPU resources on my server. My test consumed 380MB for 2 keys.
Checked how many tokens are stored per request and the memory cost per token. After adding debugging, found that my run did not cause rapid DRAM growth — memory usage matched the token count times per-token cost.
...and more contributions not listed here
Responsibilities:
vLLM Research & System Architecture Analysis - Conducted in-depth research into vLLM internals and execution flow, as well as a detailed study of Dynamo’s architecture to fully understand system behavior, request flow, and end-to-end pipeline dynamics.
Hyper-Converged KV-Cache Offloading – Specialized in vLLM infrastructure and memory optimization within a hyper-converged design, with hands-on experience using Dynamo and LMCache for efficient KV-Cache management and KVRocks for key-value storage. Deployed and executed Dynamo on containerized environments using Docker, applying system-level optimization techniques to improve cache locality and inference performance.
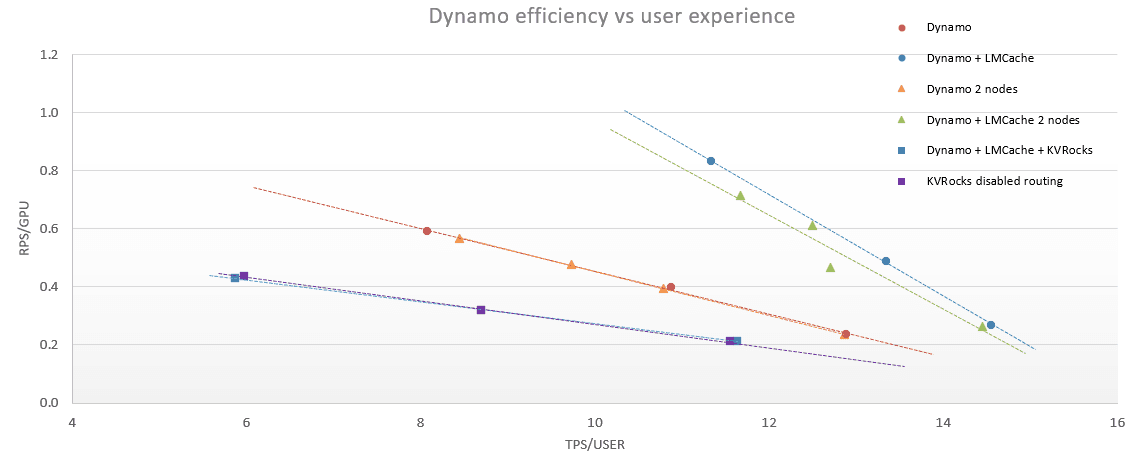
High-Performance Profiling & Benchmarking - Performed deep profiling and performance analysis on high-end GPU servers, benchmarking three inference pipelines, identifying critical bottlenecks, and achieving up to a 2× improvement in TPS and RPS per user when comparing LMCache-accelerated runs (storing KV-Cache on DRAM) against Vanilla vLLM runs.
Distributed Deployment & Scalability Validation Deployed Dynamo + LMCache across a distributed multi-node environment to validate scalability, maintain throughput, and ensure consistent performance under distributed load.
Hyper-Converged Architecture Optimization - Removed and optimized aware-routing mechanisms to enable a fully hyper-converged architecture, significantly reducing system network load and simplifying traffic patterns.
...and more contributions not listed here
Responsibilities:
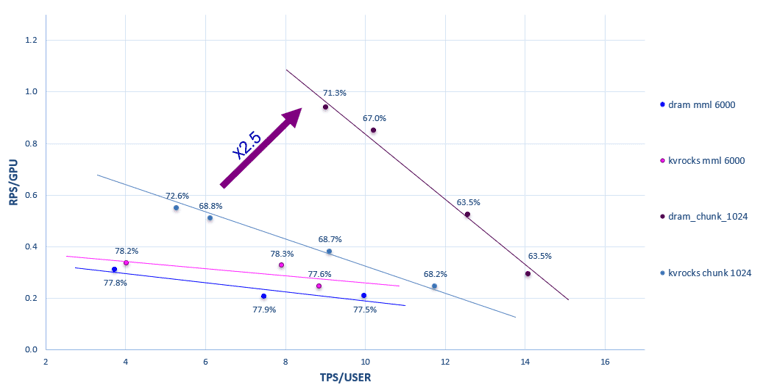
Research: Conducted a comparative study on "KV-Cache Offloading": Benchmarked vLLM with KVrocks (SSD) vs. DRAM to quantify cost-performance trade-offs
Provisioned a high-throughput RAID0 array across dual 15TB NVMe SSDs specifically to accelerate KVrocks I/O operations
Deployed the open-source vLLM framework on NVIDIA L4 GPUs to establish a baseline environment for Llama-3-8B inference
Engineered the integration of vLLM with LMcache and KVrocks, enabling the chunk-based redirection of KV-cache blocks from GPU memory to local storage
Calculated precise concurrency limits by analyzing HBM saturation points relative to token size and KV-cache footprint
Optimized RocksDB parameters (compression, write buffers) to minimize storage latency under high concurrent user loads
Enhanced the Python benchmarking script by implementing timeout exception handling to filter data skew and ensure accurate TPS metrics
Synthesized benchmark data into comparative DRAM vs. SSD graphs plotting RPS/GPU vs. TPS/USER, illustrating the cost-performance trade-offs
...and more contributions not listed here
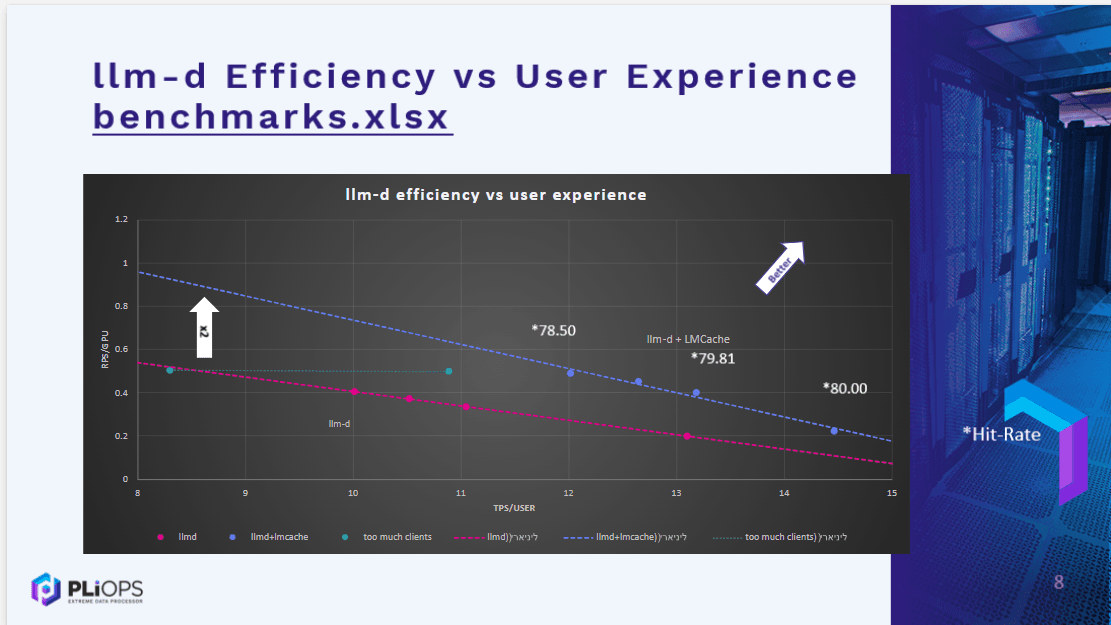
Responsibilities:
• Contributed to an R&D team developing data-center-scale infrastructure for high-performance LLM inference.
- Deep Exploration of vLLM & LLM-D Architecture Led a comprehensive exploration of vLLM’s internal mechanisms and execution model, alongside an architectural breakdown of llm-d. This included mapping request lifecycles, understanding component interactions, and characterizing the full behavior of the inference pipeline from input to output.
- KV-Cache Optimization in a Hyper-Converged Environment Engineered a hyper-converged setup for KV-Cache offloading, leveraging LLM-D and LMCache to streamline cache handling and KVrocks for persistent key-value storage. Implemented memory- and system-level optimizations that improved cache locality and boosted inference stability and throughput
- GPU Performance Profiling & Multi-Pipeline Benchmarking Executed rigorous profiling sessions on advanced GPU clusters, evaluating three different inference pipelines. Identified performance constraints and delivered up to 2× gains in TPS and RPS per user when comparing LMCache-backed (DRAM-cached) runs against baseline vLLM execution paths.
- Kubernetes-Based Deployments (Single-Node & Multi-Node) Implemented both single-node and multi-node deployments of LLM-D and LMCache on Kubernetes clusters, enabling reproducible performance testing, streamlined rollout strategies, and consistent behavior across environments
- Hyper-Converged Routing Simplification & System Streamlining Redesigned routing behavior by removing storage-aware routing dependencies, enabling a truly hyper-converged inference architecture. This optimization significantly reduced network overhead, simplified data paths, and improved the system’s operational efficiency.
...and more contributions not listed here